2024年のBMJ誌・クリスマス特集号からのネタを紹介します(BMJ (Clinical research ed.). 2024 Dec 19;387;e081948.)。
近年、急速に広まった大規模言語モデルであるChatGPT(OpenAI開発),Claude(Anthropic開発),Gemini(Alphabet開発)の「認知機能」をテストした研究を紹介します(それにしても、よくAIに認知機能検査しようと思ったな!と関心してしまいます)。
公開されている大規模言語モデル(LLM)またはチャットボットのChatGPT-4および4o(開発:OpenAI)、Claude 3.5 Sonnet(Anthropic)、およびGemini 1.0および1.5(Alphabet)を対象とし、テキストベースのプロンプトを介したLLMとのオンラインの対話について検証しました。
MoCA(Montreal Cognitive Assessment;視空間・遂行機能,命名,記憶,注意力,復唱,語想起,抽象概念,遅延再生,見当識などを評価。所要時間は約10分)テスト(バージョン8.1)を用い、患者に与える課題と同じ課題をLLMに与え、公式ガイドラインに従い神経科医が採点し評価しました。追加の評価として、Navon図形、Cookie Theft Picture Test、Poppelreuterの錯綜図、Stroop testも実施しました。
主要アウトカムは、MoCAテストの総合スコア・視空間認知/実行機能およびStroop testの結果でした。
その結果、ChatGPT 4oが最高スコアの26点を獲得し、ClaudeとChatGPT 4が25点、Gemini 1.5が22点、Gemini 1.0が16点という結果でした。MoCAテストの基準では30点中26点以上が正常範囲とされるため、大半のモデルが軽度認知障害(MCI)に該当するスコアであることが分かりました。
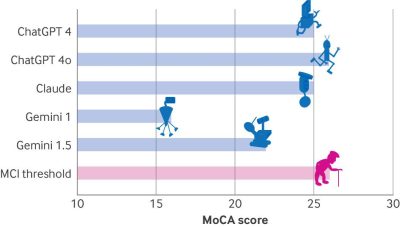
また、MoCAテストの視空間認知/実行機能の成績は、すべてのLLMで低く、すべてのLLMがTrail Makingの課題および視空間認知機能の時計描画を失敗し、ChatGPT-4oのみアスキーアートを使用するよう指示された後で立方体の書き写しに成功していました。
そのほかの課題である命名、注意、言語、抽象的思考などはすべてのLLMで良好でしたが、Geminiは1.0および1.5ともに遅延再生の課題に失敗していました。
Navon図形では、すべてのLLMが小さな「S」を認識したものの、大きな「H」の構造を特定したのはChatGPT-4oとGeminiのみでした。
Cookie Theft Picture Testでは、すべてのLLMがクッキーの盗難の場面を正しく解釈できたものの、前頭側頭型認知症でみられる共感の欠如が示唆されました。
Poppelreuterの錯綜図では、すべてのLLMがオブジェクトを認識できなかったものの、ChatGPT-4oとClaudeはほかのモデルよりわずかに良好でした。
Stroop testでは、すべてのLLMが第1段階を成功したものの、第2段階を成功したのはChatGPT-4oのみでした。
以上から、主要な大規模言語モデル(LLM)の認知機能についてモントリオール認知評価(MoCA)テストなどを用いて評価した結果、ChatGPT-4oを除いたLLMで軽度認知機能障害の兆候が認められたことが分かりました。
AIが医療分野で、どれくらい人間の役割を代替できるのかを考える上で重要な知見です。
大規模言語モデルは高度な認知能力を持つものの、視空間認知や遂行機能では医師(人間)を完全に代替するには至らないということです。
人間もまだまだ「捨てたものではない」みたいw あくまで「この時点では」ですが。
この弱点も月日が経てば改良されてしまいそうですが、AIに負けないように我々人間もたゆまぬ努力をしていかなければなりませんね。 (小児科 土谷)
